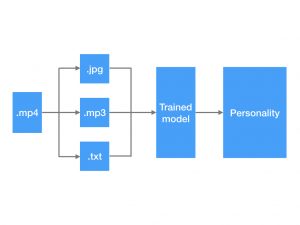
 性格分析は心理テストの延長線上として扱われることが多かったが、近年では新卒採用時の志向性判断、上司との関係性チェックなど企業での生産性を向上させるためのツールの一種として扱われるようになった。しかし一定の信頼性を持つ性格分析を行うには大量の項目があるアンケートに回答する必要があり、導入する難易度は低くない。本研究は動画データを画像、音声、書き起こし文字などの複数のデータ形式へ変換しそれぞれの形式に適した方法で特徴量変換を行いマルチモーダルな入力としてモデルを学習させ登場話者の性格を予測するモデルを提案し、信頼性の担保された性格分析を導入コストを下げて提供することを目的とする。
性格分析は心理テストの延長線上として扱われることが多かったが、近年では新卒採用時の志向性判断、上司との関係性チェックなど企業での生産性を向上させるためのツールの一種として扱われるようになった。しかし一定の信頼性を持つ性格分析を行うには大量の項目があるアンケートに回答する必要があり、導入する難易度は低くない。本研究は動画データを画像、音声、書き起こし文字などの複数のデータ形式へ変換しそれぞれの形式に適した方法で特徴量変換を行いマルチモーダルな入力としてモデルを学習させ登場話者の性格を予測するモデルを提案し、信頼性の担保された性格分析を導入コストを下げて提供することを目的とする。
Project
動画からのマルチモーダル人物性格判定
Related Member
Copyright © Oka Laboratory. All rights reserved.